Let's talk a little bit about overlay networks that we generally hear when the topic is distributed systems. An overlay network is a network which is located (virtually) on another network. It is actually kind of similar to multi layer concept. You have another layer to help other layers do some operations.
Wiki has again a clear definition for this concept which is " . Nodes in the overlay can be thought of as being connected by virtual or logical links, each of which corresponds to a path, perhaps through many physical links, in the underlying network" .
Cloud computing is one of the examples for overlay networks. The nodes run on top of the Internet.
< more details will be outlined soon as more particulars will be covered >
Monday, May 14, 2012
Thursday, May 3, 2012
IP Multicast and CacheCast
Single Source Multiple Destinations Data Transmission in the INTERNET
Let's first mingle with the terms that we are supposed to know before going into particulars of this topic.
There are 3 ways of addressing with IPv4 standard.
Unicast : One sender -> One destination
In computer networking, unicast transmission is the sending of messages to a single network destination identified by a unique address.

What is Broadcast ?
Let's say that we have 1000 receivers, and our bandwidth is 30mbps. What happens if we want to send a package to all of these destinations ? Let's do the math in case of broadcasting. We need to have 30 gbps in order to send this packet to 1000 destinations. What the heck :) , right ? Content is same, though.
"Broadcast is when a single device is transmitting a message to all other devices in a given address range. This broadcast could reach all hosts on the subnet, all subnets, or all hosts on all subnets. Broadcast packets have the host (and/or subnet) portion of the address set to all ones. By design, most modern routers will block IP broadcast traffic and restrict it to the local subnet." http://www.inetdaemon.com/tutorials/internet/ip/addresses/unicast_vs_broadcast.shtml
What is Multicast ?
Wiki has a clear definition as usual :
In computer networking, multicast is the delivery of a message or information to a group of destination computers simultaneously in a single transmission from the source.
 | |
| http://upload.wikimedia.org/wikipedia/commons/3/30/Multicast.svg |
Ok so we have one source and purpose is to send a message from that source to multiple destinations. .
"This allows for communication that resembles a conference call. Anyone from anywhere can join the conference, and everyone at the conference hears what the speaker has to say. The speaker's message isn't broadcasted everywhere, but only to those in the conference call itself. A special set of addresses is used for multicast communication." http://www.inetdaemon.com/tutorials/internet/ip/addresses/unicast_vs_broadcast.shtml
What about CacheCast?
Note that as you can understand from the existence of each new technology, there is always a problem with the current system, maybe some optimizations need to be done for system to behave in a better manner such as speed, security and so on, and as a result of this need a new solution is produced.
Here, CacheCast is a solution for the conditions that today's internet causes when dealing with Multicast. However it does not solve the problems in the network layer, it does so in the link layer by caching.
Here is the outline of this post .
- Multicasting in the Internet
- Basis and critique
- CacheCast
- Internet Redundancy
- Packet caching systems
- CacheCast Design
- CacheCast Evaluation
- Efficiency
- Computational complexity
- Environmental impact

{kind=link}
Multicasting in the Internet
In the beginning of the internet, in order to send a package to multiple destination it had to be in unicast style meaning that a source needs to send its message to multiple destinations separately in different times.

By this way we can save bandwidth and link capacity.
There has been two solutions for doing this multicast. The first proposed one was to add the list of receivers' name into the packet so that it will be replicated in the internet and destinations will receive it as shown in the picture below.


As you can see list is so long that there is a small space for the actual message "Hi".
The best thing to do with this approach is to have a small list of receivers and sending them separately. This approach briefly does not scale well.
The second approach is to create groups and putting individuals into that groups. Network is responsible for replicating the data among groups and individuals.

To compare these two approaches, we can point that adding each individual into the list like in the first approach and sending it to the network makes the packet size huge as the size of the list grows bigger. However the second approach does not have such problems.
Ok now we focus on the second approach (group based one) . We have one source, we specify which group we want to send the package to, and network handles remaining parts of the operation such as replication. However network replicates the data regardless of knowing who the sender is. It might be dangerous if the sender is malicious.
In the beginning, when if a node needs to join a channel (where there exists a group and individuals of this group are able to benefit from that channel) , there was no verification or authorization,. Anyone could join, transmit. It was open .
Then multicast evolved, only sender became able to send packages. It was the one who has the total control of everything. It was called single source multicast.
Afterwards, many protocols showed up to improve however deployment of Multicast did not grow because of the problems discussed before. Security, congestion control issues have not been solved.
Multicast has some inherited problems in its architecture. Extremely distributed protocol might be developed that handles group management, but deployment of such protocol is not that possible since it involves the change of routers in the internet in terms of software updates.
Did IP multicast fail ?
This is a type of network that Internet provider has the total control like IPTv, no one else can use this IPmulticast from outside of the network.
Single source multiple destination transport mechanism becomes fundamental !
However at present, Internet does not provide efficient multi-point transport mechanism.
In conclusion, we mentioned 2 approaches. First one is "Datagram routing for internet multicasting" ( explicit list of destinations in the IP header ) which did not scale well and died.
Second one is "Host Groups" . It is now taken as a reference and new improvements are being tried on that area.
These two approaches take place in network layer.
Moreover a third approach has showed up which is type of peer to peer network. Clients receive input from server and give it to another clients to reduce server's burden. But this solution is on the application layer which creates redundancy on the links. However even though we reduce the burden of server, clients use unicasting to send the data to others. It creates redundancy on the links.
CacheCast
Let's first talk a little bit about redundancy. The source of redundancy is that the server transmits the same data over and over again to multiple destinations.

The idea to solve this problem is packet caching. Let's first check the graph below.


Basically we cache payload locally. However you might ask some questions such as;
- How to determine whether a packet payload is in the next hop cache ?
- How to compare packet payloads ?
- What size should the cache be ?
CacheCast is example of packet caching system answers these questions in the following way.
Let's remember some terms such as link and router.
Link is a logical point to point connection.
Its throughput is limited in bit per second. So it is beneficial to avoid redundancy.
Router is a switching node. It performs three main tasks per packet.
- TTL update
- Checksum recalculation. ( considering check sum of IP header )
- Destination IP address lookup.
These tasks do not depend on packet size.
For router it does not matter how big the packet-payload is.
The burden for router is to determine the destination IP address lookup.
So what is Link Cache about ?

Caching is done on per link basis.
Cache management unit (CMU) removes payloads that are stored on the link exit.
Cache store unit (CSU) restores payloads from a local cache. It is like a remote memory.
Link cache size must be minimized. After approx. 72ns on a 10 Gbps link, the link gets in idle mode that's why. And modern memory r/w cycle is appr. 6-20 ns. It means that link processing must be simple to take operation in this limited time.
And to talk about link queue, at present it is scaled to 250 ms of the traffic meaning that if we want to build a link queue for 10 Gbps link, we need already 315 mb. The size of the memory is not the problem, read memory speed is .
The point is that a source of redundant data must support link caches.
Server Support in CacheCast
- Server can transmit packets carrying the same data with a minimum time interval
- Server can mark its redundant traffic
- Server can provide additional information that simplifies link cache processing.
Server support aims to batch same request for same data and send it in minimum time interval.
Moreover, CacheCast packet carries an extentsion header describing packet payload.
* Payload ID ( Unique payload ID - comparsion of payloads is done by this)
* Payload Size ( Size of the redundant part of the packet )
* Index ( for administration purposes )

When multiple package arrive, the redundancy is removed and other part is added into the first payload (Packet Train Concept) .
Briefly source (Server)
- Batches transmissions of the same data to multiple destinations
- Builds CacheCast Headers
- Transmit packets in the form of a packet train.
I have to period here due to the limited time. I will get it complete when I have the chance.
Monday, April 30, 2012
Mobile Adhoc Networking MANET Part 2
If we review what we have covered in the first part , we outlined
- what mobile adhoc network technology is,
- in which fields this technology is being used
- what are the requirements for adhoc routing ?
- what are the routing protocols ? AODV (one of the most preferred routing protocols)
We will continue talking about routing protocols. The outline of this post as follows ;
1) Selected Routing Protocols
- Dynamic Source Routing (DSR)
- Location Aided Routing (LAR)
- Optimized Link State Routing (OLSR)
2) Routing Dependability in Ad hoc Networks
3) Performance Evaluation of Ad hoc Networks
Let's start with what we have as Routing Protocol except AODV .
1) Selected Routing Protocols
Dynamic Source Routing (DSR)
- Very similar to AODV- It is a reactive protocol (on demand)
- No proactive mechanisms.
- When I want to send a packet to destination , I find a route. ( I do not know where the destination is, flooding happens like in AODV)
A different thing with DSR is, each node appends its own identifier when forwarding RREQ (Request message) . Therefore RREQ grows in each hope.

In this figure, S wants to send a package to D but does not know the route. Therefore, it start flooding the message. First it sends it to its neighbours (B,C,E) , then it goes on like that. C sends the message to H,G ; and B sends it to A,H (For instance in this case, H receives packet RREQ from two neighbors which might mean a potential collision). However we do not care about collision, because the network is dense and I just would like to reach collision, even if there happens a collision most probably another node will send the message to H again, maybe A and I nodes in this case.
As you can see in the figure, each node that receives the packet adds its own identity into the message.

When message packet reaches D, D knows that it is for him and stops broadcasting it. And then RREP is sent by D from the reverse path. ( Rout reply can be sent by reversing the route in Route Request (RREQ) only if links are guaranteed to be bi-directional. IF unidirectional (asymmetric) links are allowed which means that "Ok, D knows that S sent the message from the path S->E->F->J->D, what happens if link from F to J (F->J) is asymmetric meaning that there is no way back from J to F in which case reverse path cannot be used " * . That's why, another route discovery from S to D is handled to find a path of which reverse path can be used in order to send the reply back . This happens of course if D does not have a route back to S.
* It might happen when message is delivered to the destination but later on a link back is broken ( maybe destination is out of the range ) .
Some extra mechanisms like we use in AODV can be used in order to limit broadcast in case of a re ally big network.
You might see the obvious difference between AODV and DSR from this graph above. We do not deal with tables as we do in AODV ( you need to update tables and etc) . Here, we just need to reverse the path back to the source.

After destination receives the message, it uses the path recorded in RREQ and finds out the reverse path. There is no need to store any information in the intermediary node as we do in AODV such as having tables. Briefly the nodes between do nothing and know nothing about the route because their task it to only send the package to their neighbours. Remember ! We are only trying to find the ROUTE ! We have not sent the real packet yet. The "message" we were quoting was about RREQ message. Do not confuse with RREQ message and payload (real message) .
After finding the route ;
The information about route is stored in only S and D.

As you can see, source specifies the route. But here is the thing about DSR. Ok route is known, but when S sends DATA to E, E will add its own information into the DATA Message packet header, right ? Imagine this is repeated each time the data is given to the next node. Instead of DATA[S,E,F,J,D] we will come up with IP addresses and stuff.
This will definitely cause overhead.
That's all what we need to know about DSR :) .
To recap , we have no tables unlike AODV. There might be some overhead as the route grows.
We have talked about Reactive Protocols (AODV and DSR) , now it is time to cover some Proactive Protocols.
* Location information may be obtained using GPS.
LAR defines an expected zone. I know some information about the topology, I have some idea where destination could be. By this way, I can calculate the zone so that I do not need to waste my source by flooding message over the whole network.
Expected region is calculated based on potentially old location information and knowledge of the destination's speed.
There is also another term request zone which means a zone in that source and destination nodes exist.
Let's have a look at this graph below.

As you can imagine, when S wants to send a message to D, the nodes that will spread the message through D are restricted in the Request Zone. If a node out of the request zone such as A receives the message, it checks its zone and sees that he is not in the zone so that he will not flood that message any longer.
However it could be more efficient if some nodes inform Source about estimated request zone in more accurate manner, right ? Some nodes might have more recent information and it would be better if we could make use of those information.
This newly found, discovered request zone by the help of other nodes within the zone is called "Adaptive request zone".
* Reduces overhead of route discovery
* Another thing is that there is no way of overcoming a situation like shown below.
Let's assume that blue zone is our request zone and there is our destination in the corner of that zone (blue square) . However there is a barrier (obstacle) in front of that node depicted as red lines that does not let us reach our destination. Only solution seems to go other way around the red line which is not possible because it is out of our request node. Therefore in such cases, we might end up with some dead end.

Optimized Link State Routing (OLSR)
We are able to limit flooding without physical location as mentined briefly before. If we have a known route, we might take it as a reference and create a rule from that for new discovery. We might state that route requests are propagated only along paths that are close to the previously known route.
Closeness property defined without using physical location.
OLSR is designed for different types of networks.
How does it work ?
Link state routing is proactive. It has all information before we need them. And local information is disseminated network wide. You are basically monitoring everything.
It is actually very similar to Standard Internet Routing. Therefore there is overhead, and the question is it really applicable for adhoc networks ?
There must be some optimizations. So, I will broadcast my local information to whole network, right. But while I do it in OLSR, it applies an optimized version of flooding which aims to broadcast a message only to selected neighbours. It is called multipoint relays (MPR) . MPR is the key feature of OLSR.
How does MPR work ?

MPR selection : We can add some info into Hello messages, and we can calculate 2 hops neighbors.
Link State Messages : If we have an updated link information about something, and if others need to know it we just relay this information.
However in OLSR, I select two or three multipoint relays and can reach all of my neighbors. Briefly for Large and Dense network networks it is feasible and makes sense to use OLSR .
Moreover, OLSR has low latency. Because we have a routing table. When I want to send a packet, I check my table and just send it. Compared to that, AODV has to discover route when needed , reply back and stuff. OLSR has that information on hand.
Recall that in ad hoc networks, there is mobility, dynamic situations.
In this part, our concern is Routing system.
 Routing protocols need to find out whom to communicate , which path to choose.
Routing protocols need to find out whom to communicate , which path to choose.
How can we characterize routing system shown as a box in the graph above ? This is what we will outline now.
We also need to define what Routing Dependability is. It is trustworthiness of a routing system.
Well-behaving nodes : that works, forwards the packet.
Malicious nodes : the ones that inject false information into messages or remove them completely from the network ( black holes) .
It has been proven that if the number of selfish nodes increases, the packet loss in the network increases linearly as well.
Besides that, in case of AODV, if there are many selfish nodes in the network we need to incerase the number of control messages ( to keep the track of what is going on in the network , and reestablish route if a node does not forward the packet ) . It results in increase of routing overhead.
Selfish nodes: the ones that receives the packet but do not forward it .
How to measure dependability ?
There are many metrics for this purpose such as sent packets (bytes) , Lost packets (Bytes) , mean end to end delay , mean path length, maximum path length, total # of RREQ, RREP, RERR . The metrics you would select are totally up to what routing protocol you choose.
- Induced by mobility : High topology dynamics
- Induced by wireless communication
- Induced by node misbehavior ( we might want to add some extra mechanisms to overcome this)
You need to know what you want to characterize in your system. You need to have a proper goal first. There is no such thing as general model.
Goals -> correct metrics, workloads, methodology.
Your performance evaluation should represent the actual usage of the system.


Challenge : Qualify and quantify the effects of
node misbehavior on the overall performance of the routing system.
We would like to see how the system behaves.
What about choice of evaluation technique ?
- Real world observations are not possible because there is no large scale MANET, and it would be expensive to set up a new one.
- Emulation / Testbed experiments are possible but in a small scale.
- Simulation studies are being conducted.
Compared to real world observations, we can play with the settings of input and output values in emulation, simulation experiments. I can define input, predict output. Workload would be input and calculations could be output.
Below you can see the result of an experiment.

It is for sure that there are many issues need to be handled if an optimized ad hoc network needs to be implemented which does not seem possible with today's technology.
For instance what if after 2 hops away the speed is decreasing while it is pretty fast in the nodes close to the source ? Should I buffer it ? or what ? I need some flow control mechanisms to deal with these kind of problems. Another problem would be priority ? which packet is important , my packet or neighbours' ? A lot of research is being done on these issues.
What about security ? What if there is DoS attacks ? Some malicious nodes can use a specific node just to kill its battery. How can we overcome it ? or malicious nodes can temper messages , who can prevent it and how ?
Smart antennas might change the future of ad hoc networks.
Self organizing, mobile and wireless nodes
Absence of infrastructure, multi-hop routing necessary
System are both terminals ( end systems ) and routers (nodes)
Routing is a main problem in ad hoc networks
Resources : The content of this post has been generated from the slides of the presentation that was given by Matthias Hollick in UIO in 2007.
Some extra mechanisms like we use in AODV can be used in order to limit broadcast in case of a re ally big network.
You might see the obvious difference between AODV and DSR from this graph above. We do not deal with tables as we do in AODV ( you need to update tables and etc) . Here, we just need to reverse the path back to the source.

After destination receives the message, it uses the path recorded in RREQ and finds out the reverse path. There is no need to store any information in the intermediary node as we do in AODV such as having tables. Briefly the nodes between do nothing and know nothing about the route because their task it to only send the package to their neighbours. Remember ! We are only trying to find the ROUTE ! We have not sent the real packet yet. The "message" we were quoting was about RREQ message. Do not confuse with RREQ message and payload (real message) .
After finding the route ;
The information about route is stored in only S and D.

This will definitely cause overhead.
That's all what we need to know about DSR :) .
To recap , we have no tables unlike AODV. There might be some overhead as the route grows.
We have talked about Reactive Protocols (AODV and DSR) , now it is time to cover some Proactive Protocols.
Location Aided Routing (LAR)
LAR is more detailed than AODV and DSR in this manner. It is actually designed as an extension of DSR. It has some extra features. As its name states, it gives information about location of the nodes. By this way, broadcasting can be limited.* Location information may be obtained using GPS.
LAR defines an expected zone. I know some information about the topology, I have some idea where destination could be. By this way, I can calculate the zone so that I do not need to waste my source by flooding message over the whole network.
Expected region is calculated based on potentially old location information and knowledge of the destination's speed.
There is also another term request zone which means a zone in that source and destination nodes exist.
Let's have a look at this graph below.

As you can imagine, when S wants to send a message to D, the nodes that will spread the message through D are restricted in the Request Zone. If a node out of the request zone such as A receives the message, it checks its zone and sees that he is not in the zone so that he will not flood that message any longer.
NOTE ! Each node has to know its physical location to determine whether it is within the request zone or not.
On condition that route is not found in the request zone due to miscalculation of request zone (destination node might move faster than expected) , we can always extend the request zone .However it could be more efficient if some nodes inform Source about estimated request zone in more accurate manner, right ? Some nodes might have more recent information and it would be better if we could make use of those information.
This newly found, discovered request zone by the help of other nodes within the zone is called "Adaptive request zone".
! Recall that LAR is like an extension of DSR. In LAR we are keeping the track of the location of each node + we also have route information as DSR has. We can make use of route information in such a way that next discovery can be based on this previously determined route. For instance, we might limit the broadcast or flooding by stating that new route should include at lease two-three nodes of the old one.
Advantages of LAR
* Reduces the scope of route request flood* Reduces overhead of route discovery
Disadvantages of LAR
* We need more information (location of nodes)* Another thing is that there is no way of overcoming a situation like shown below.
Let's assume that blue zone is our request zone and there is our destination in the corner of that zone (blue square) . However there is a barrier (obstacle) in front of that node depicted as red lines that does not let us reach our destination. Only solution seems to go other way around the red line which is not possible because it is out of our request node. Therefore in such cases, we might end up with some dead end.

Optimization for LAR
Optimized Link State Routing (OLSR)
We are able to limit flooding without physical location as mentined briefly before. If we have a known route, we might take it as a reference and create a rule from that for new discovery. We might state that route requests are propagated only along paths that are close to the previously known route.
Closeness property defined without using physical location.
Optimized Link State Routing (OLSR)
The name of the protocol says much about its functionality. So far, we had protocols that are reactive, not updating routing information all the time because it is costly and network is so dynamic and so on.OLSR is designed for different types of networks.
How does it work ?
- It floods status of its links
- Re-broadcasts link state information received from its neighbor.
- Keeps track of link state information received from other neighbors.
- Uses these information to determine next hop to destinations.
Link state routing is proactive. It has all information before we need them. And local information is disseminated network wide. You are basically monitoring everything.
It is actually very similar to Standard Internet Routing. Therefore there is overhead, and the question is it really applicable for adhoc networks ?
There must be some optimizations. So, I will broadcast my local information to whole network, right. But while I do it in OLSR, it applies an optimized version of flooding which aims to broadcast a message only to selected neighbours. It is called multipoint relays (MPR) . MPR is the key feature of OLSR.
How does MPR work ?

A node is selected with two rules ;
1) Any 2-hop neighbor must be covered by at least one multipoint relay. In our example above, A's multipoint relays are node C and E in order to reach G and H.
2) The number of multipoint relays should be minimized (per node)
2) The number of multipoint relays should be minimized (per node)
Core features of OLSR
Link sensing : By sending Hello messages to the neighbors, we can learn about our neighbourhood.MPR selection : We can add some info into Hello messages, and we can calculate 2 hops neighbors.
Link State Messages : If we have an updated link information about something, and if others need to know it we just relay this information.
Conclusion for OLSR
Ok so, it seems a bit complicated, a lot of overhead. But it is well suited for some networks ( Large, Dense networks ) . Because, If have many neighbours and prefer to use AODV, I have to send them all my messages which means a lot of overhead.However in OLSR, I select two or three multipoint relays and can reach all of my neighbors. Briefly for Large and Dense network networks it is feasible and makes sense to use OLSR .
Moreover, OLSR has low latency. Because we have a routing table. When I want to send a packet, I check my table and just send it. Compared to that, AODV has to discover route when needed , reply back and stuff. OLSR has that information on hand.
2) Routing Dependability in Ad hoc Networks
- The effects of node misbehavior.
- Modelling adhoc networks.
Recall that in ad hoc networks, there is mobility, dynamic situations.
In this part, our concern is Routing system.

How can we characterize routing system shown as a box in the graph above ? This is what we will outline now.
We also need to define what Routing Dependability is. It is trustworthiness of a routing system.
Node Misbehavior
A node in the middle may keep the message and not forward to package. It can affect the overall performance of the system. There are three different nodes.Well-behaving nodes : that works, forwards the packet.
Malicious nodes : the ones that inject false information into messages or remove them completely from the network ( black holes) .
It has been proven that if the number of selfish nodes increases, the packet loss in the network increases linearly as well.
Besides that, in case of AODV, if there are many selfish nodes in the network we need to incerase the number of control messages ( to keep the track of what is going on in the network , and reestablish route if a node does not forward the packet ) . It results in increase of routing overhead.
Selfish nodes: the ones that receives the packet but do not forward it .
How to measure dependability ?
There are many metrics for this purpose such as sent packets (bytes) , Lost packets (Bytes) , mean end to end delay , mean path length, maximum path length, total # of RREQ, RREP, RERR . The metrics you would select are totally up to what routing protocol you choose.
Routing Dependability Problems
- Most ad hoc routing algorithms assume only well-behaving nodes to support multi-hop operation of the network. However if something goes wrong in between, everything can be affected in a negative way.
- Induced by mobility : High topology dynamics
- Induced by wireless communication
- Induced by node misbehavior ( we might want to add some extra mechanisms to overcome this)
3) Performance Evaluation of Ad hoc Networks
Basic Terms- Performance Analysis = Analysis + Computer Systems
- System = any collection of hardware + software
- Metrics = the criteria used to evaluate the system performance
- Workloads = the requests made by the users of the system
You need to know what you want to characterize in your system. You need to have a proper goal first. There is no such thing as general model.
Goals -> correct metrics, workloads, methodology.
Your performance evaluation should represent the actual usage of the system.

How to analyze (Mobile Ad hoc ) networks ?

Challenge : Qualify and quantify the effects of
node misbehavior on the overall performance of the routing system.
We would like to see how the system behaves.
What about choice of evaluation technique ?
- Real world observations are not possible because there is no large scale MANET, and it would be expensive to set up a new one.
- Emulation / Testbed experiments are possible but in a small scale.
- Simulation studies are being conducted.
Compared to real world observations, we can play with the settings of input and output values in emulation, simulation experiments. I can define input, predict output. Workload would be input and calculations could be output.
Below you can see the result of an experiment.

Challenges in Ad hoc Networks
- Security,
- QoS,
- Scalability,
- Heterogeneity,
- Adaptation,
- Dependability.
It is for sure that there are many issues need to be handled if an optimized ad hoc network needs to be implemented which does not seem possible with today's technology.
For instance what if after 2 hops away the speed is decreasing while it is pretty fast in the nodes close to the source ? Should I buffer it ? or what ? I need some flow control mechanisms to deal with these kind of problems. Another problem would be priority ? which packet is important , my packet or neighbours' ? A lot of research is being done on these issues.
What about security ? What if there is DoS attacks ? Some malicious nodes can use a specific node just to kill its battery. How can we overcome it ? or malicious nodes can temper messages , who can prevent it and how ?
Smart antennas might change the future of ad hoc networks.
Summary
MANET :Self organizing, mobile and wireless nodes
Absence of infrastructure, multi-hop routing necessary
System are both terminals ( end systems ) and routers (nodes)
Routing is a main problem in ad hoc networks
- Topology based, destination based, hierarchical, geographical, cluster-based, etc. strategies,
- Proactive, reactive, hybrid, etc. protocols.
- Problems persist: QoS, Security, Scalability, Heterogeneity, ...
Resources : The content of this post has been generated from the slides of the presentation that was given by Matthias Hollick in UIO in 2007.
Sunday, April 29, 2012
Mobile Adhoc Networking MANET Part 1
We will outline Mobile Ad hoc Network technology in this post.
Content of this post is as follows ;
1) Introduction and Motivation
2) How is Routing in Mobile Adhoc Networks
3) Selected Routing Protocols (1)
* Ad hoc on-demand distance vector routing protocol ( AODV )

1) Introduction and Motivation
Let's first talk about wired and wireless networks
These aspects are explained pretty well by Julien Thomas. Let's see his explaination.During the past years, wireless networks have widespread due to new technologies such as BlueTooth [IEEE 802.15] and WiFi [IEEE 802.11]. Contrary to wired networks, these networks do not rely on physical links. They can thus provide new services, such as easy access to the Internet (using hotspots1.1) or access to private networks (domestic or professional) without having to install cables. However, this mean of communication calls into question several assimilated notions in wired networks. For instance, as anybody can try to access to the network or to eavesdrop communications, access management have to be reconsidered. Moreover, some wireless networks do not rely on a logic infrastructure, which complicates the problem, for instance for the services management, as presented in the next section.
http://master.julienthomas.eu/rapports/html/rapport-node8.html ////
Differences between several wireless networks
Due to the fact that they are used to provide high level services, such as Internet connexions, the most widespread wireless networks are those relying on an infrastructure. As their names suggest, these networks are built in a logic way, respecting a stable infrastructure, in particular for the routing management. Thus, all the administration functions are managed by an Internet Service Provider (ISP), which provides a simple and reliable service.
The wireless networks without infrastructure are auto-built networks. These networks (called MANET 1.2, Mobile Ad hoc NETwork) rely on network's nodes to satisfy all the network functioning's needs, in particular the routing politics. The network management is thus dynamic and dependent on its nodes. These networks offer new services, such as easy and fast deployment of systems, without having to envisage an administration structure (the deployment of a communicating captors network is an example of such systems). However, the lack of infrastructure leads to weakness, which can be for example exploited to limit the network availability (see section http://master.julienthomas.eu/rapports/html/rapport-node8.html ////
Wiki says : A mobile ad-hoc network (MANET) is a self-configuring infrastructureless network of mobile devices connected by wireless links. ad hoc is Latin and means "for this purpose".[1][2]
 | |||
| http://www.ece.iupui.edu/~dskim/manet/images/adhocnet.gif |
All of the devices in the picture above work as a router that directs the traffic to another if it does not need that packet.
Basics
- Principle is to create a communication without any infrastructure .
- Devices can communicate with each other using short range communication.
- Multihop routing is necessary.
- Spontaneous networks can be supported by Ad hoc networks
- Self-organizing, mobile and wireless nodes.
- Systems are both terminals (end systems) and routers (nodes)
Characteristics
- Dominated by heterogeneity and variability.- Different routing behaviors of different devices.
- Mobility characteristics ( Speed, predictability ) , Wireless characteristics( limited range, transmission errors) , application characteristics (P2P , real time) , system characteristics (distribution, absence of infrastructure) all of them have some effects.
Note : Adaptation is crucial.
For instance,
I would like to send a message to a mobile device by using adhoc network, however how can I use his IP ? because IP has no topological meaning in this concept, he moves around so his IP changes all the time ? This is one of the biggest problems to overcome in adhoc networks.
Some Ad-hoc Applications
- Military applications ( soldiers, tanks , planes ... )
- Civilian applications ( car to car communication, emergency services, sensor networks, ... )
Let's give an example related to home networking;
We do not want to deal with cables at home, right :) generally it is a big mess. Speaker has a cable to the TV , DVD player has another and so on. Instead of these cables, would not it be great if they communicate with each other without cables ?
Another example can be a system that warns you before something happens. For instance, a system that stops your car before hitting the car in front of it .
Peer to Peer vs AdHoc ?
People mix these terms . They are similar but not same .
First of all Adhoc network focuses on network layer while P2P focuses on app layer.
P2P networks replicate data and data is distributed widely. It may not be the case in Adhoc networks.
What about Mesh network ?
We can say that Mesh network includes both sensor networks and ad hoc networks.
Characteristics ;
- Multihop communication to reach destinations.
- Self-forming , self-healing, self-organizing
- Weak mobility and power constraits.
Compared to Adhoc networks ;
- There is wireless infrastructure
- They enable easy integration of different radio technologies.
- Additional capabilities ; sophisticated algorithms can be applied.
About Ad hoc Routing -
Why do we need a specialized ad hoc routing ?
- To deal with topology dynamics caused by mobility
- To reach nodes that have no direct neighbours.
- To match characteristics of wireless communication.
- To support spontaneous formation of network
- To operate without fixed infrastructure
- Because all end systems are also acting as routers
Actually the correct answer is "there is no incorrect option". All of them are the reasons why we need a specialized ad hoc routing. There are some protocols to meet these requirements.
Requirements for Ad hoc routing
The routing protocol needs to deal with these dynamics.
- The routing protocol needs to converge fast !
- It has to minimize signaling overhead.
The routing strategy ( algorithm ) may include ;
- Shortest distance
- Minimum delay
- Minimum loss
- Minimum congestion ( load - balancing )
- Minimal interference
- Maximal signal strength
- Minimum energy (power aware routing )
! Standard Internet routing cannot fulfill these requirements !
- Because Standard Internet routing assumes there is an infrastructure, symmetrical conditions and plenty of resources. ( We have to have more dynamic systems not Standard Internet routing)
So what can we do ? let's have a look at other routing protocols .
- Flooding of Data packets : A simple solution , but results in high overhead. Some sensor network application only use flooding. It reaches the destination if there is no disconnection of nodes. There might be some situations that I do not need to do flooding.
- Uniform routing protocols : Each node shares the same responsibility. Each packet has a direct path to the destination. Uniform routing protocol has two paradigms; Proactive (table-driven) and reactive (on-demand) paradigms. Proactive protocols try to maintain routes all the time. It keeps the track of routes and when the topology happens to change, we already know the route . Reactive protocols look for a new route on demand, route discovery is handled on demand. For example, I want to send a package to a neighbour , but I do not know the route. Then I ask the route and see the topology. Because it looks for the route on demand, there is less overhead compared to proactive protocols.
- Non-Uniform Protocols. In this protocol, nodes in the network have different tasks to do. While some of them deal with routing management, others might deal with something else.
Note that "There is no protocol for adhoc routing that we can say yes it is the best one to use" .
There are many routing protocols. The picture below is just a small part of the whole picture actually.

Based on your needs, you might want to select a specific protocol considering its features.
Selected Routing Protocols (generally Preferred ones )
1) AODV
2) DSR/OLSR/LAR (these have things in common with AODV, that's why we will not cover them in this post)
AODV ( Ad hoc On-demand distance vector protocol )
- Reactive protocol ( on demand )
- All nodes are treated equally. ( they share similar responsibilities )
- Based on distance vector principle ( I have information about my neighbors and network topology , and I share it among my neighbors ) so that I have a distance vector to the destination.
- We have a route discovery cycle in AODV. We first flood-broadcast the route request thorough the network, then destination gets it. And destination replies back with the information available in the nodes' tables.
- Basic principle in AODV is to use 3 messages.
- There is no overhead on data packets.
Status : Many implementations are available (IPv4, IPv6 )
Each request has a sequence number, so if a node takes multiple requests coming from same source for same destination then it means it is a duplicate message which will be discarded. So first routing request is forwarded and others are discarded.
 | |
| http://www.cse.wustl.edu/~jain/cis788-99/ftp/adhoc_routing/fig4.gif |
Let's assume that, Node 1 tries to send a message to the destination 8. Node 1 first sends the request to its neighbours, and its neighbours do so and so on until a route/ some routes are found. Figure a depicts this propagation of Route Request (RREQ) packet . Later, destination replies back from the path which was calculated to be the fast path, the efficient one. In this case, path taken by the Route Reply Packet (RREP) is 8->6->4->1 .
Route Maintenance in AODV
AODV uses 2 timeouts to keep the route alive ; one for forward path, one for reverse path. Timeout should be long enough to allow RREP to come back. Otherwise, it might be unfortunate to assume that existing route has disappeared or broken. ( Default value for time out is 6 seconds )
Flooding is used. Because we have no information about the topology, what is the shortest path and so on. First, I need to search what is going on in the network. Using flooding makes sense for this concept. It can be of course optimized. However you need to have some extra information for optimization. Briefly we have to use flooding to get to the destination.
It also uses destination sequence numbers to determine fresh routes. By doing so, it can avoid using old/broken routes and prevent formation of loops .
 |
| From Matthias Hollick's presentation that he gave in UIO. |
You can understand what actions taken in case of a route error. I would like to explain one more time how sequence number works. Defined route has a sequence number (lets say 6 links to go for destination ) , if an error detected, system tries to find >6 (because 6 was the shortest path , and now it tries find another short path ) .
Note :AODV does not find shortest path in terms of distance , it finds the shortest path in terms of time meaning fastest path.
 | |
| From Matthias Hollick's presentation that he gave in UIO. |
For instance the graph above, we plan to reach from source 2 to destination 13 . Green path is taken as the fastest path, while dashed red line was the shortest path in terms of distance. However as you can see, even though the green line (2->20->22-> and so on) is our route, we also propagate request message in irrelevant part of the graph as well. Red arc includes the unnecessary routes.
So what to do in order to get read of unnecessary messages ?
There are some algorithms for this purpose.
- AODV -LR Local repair .
- AODV - ESP Expanding Ring Search. ( you do not flood the message through the network if you set time to live as 1 hope , so that it only checks one hope away neighbors )
IF you have a wide - dense network , AODV will fail . Because it is based on broadcasting mechanism , right ;) .
However there are multiple open issues in AODV such as Security , QoS.
These issues are being studied currently.
AODV optimizations - Gossiping (1)
- We said that that flooding is inefficient if the network is dense.Gossiping is one of the mechanisms to deal with density. Gossiping randomly selects subsets of neighbors to send the message.
AODV Extension - Multipath (2)
- Instead of dropping duplicate RREQ packets, AODVM uses RREQ table to store all RREQ information in order to have alternative ways of sending the reply back. If the nodes on the way back are mobile , or they fail whatever , why not use multipath.Resources : The content of this post has been generated from the slides of the presentation that was given by Matthias Hollick in UIO in 2006.
Saturday, April 28, 2012
RealTime Multimedia in Presence of Firewalls and Network Address Translation
Our purpose in this blog is to understand how RealTime Multimedia technologies work under the limitations caused by Firewalls and NAT devices. To give an example, you would like to connect to your laptop (which is in another network, using another rooter) by your smartphone to send something. However the firewall of your laptop blocks all the connections coming from the network where your smartphone is in. Assume that this kind of problem is occurred in real time applications such as that you would like to be able to be called anytime regardless of what infrastructure you are behind while you are outside home and changing your position so fast. Therefore the application you and the ones you are interacting with needs to adapt itself somehow and overcome the limitations of firewall and NAT devices so that no package is dropped and quality of the conversation or service could stay as planned.
First of all, for introduction, let's recall the terms we need to know to cover this topic.
I will not go into particulars but for the ones who want to know more about firewall can check this blog ; http://howto-hsk.blogspot.com/2012/03/what-is-firewall.html
But briefly guys, do not destroy your firewall ! we do not want to mess up with hackers :)
Basically Firewall ;
- Blocks all incoming traffic except established connections.
* All communication must be initiated from inside.
- Might block certain protocols
*Some vendors consider UDP dangerous.
- It keeps the track of established communication in a table located in NAT device.
* For TCP connections it is possible to take them into consideration as ESTABLISHED because TCP is a connection based protocol while UDP is connectionless meaning that UDP communication paths are considered as ESTABLISHED only if it has been responded to .
Imagine that there are lots of computers, devices conected to Internet behind FIREWALL . By NAT device, let's say located on the firewall ; these devices use only one shared, public IP address to reach outside. As far as I know using NAT devices was introduced because of lack of IPv4 adresses so that many devices could use one public IP adress for ouside the firewall. I believe that most of you have a NAT router in your home. When you use your laptop + smartphone + desktop at home, this is what is going on in your router.
NAT is divided into two groups; Source NAT and Destination NAT.
Source NAT : When you initaite a connection from inside, destination hosts out of yor firewall will see some public IPs assigned by Source NAT.
- Only receiver can detect a sender's port.
* May vary between destination hosts. ( when you communicate with a destination host you get an IP address, while for another destination host you end up with another IP address) .
Destination NAT: When you have a service that you want to allow outside world to benefit from your service which is behind a firewall, you need to tell NAT to map a port with this service so that people on the other side of the wall can access this service.
It should be stated that, firewall and NAT devices are in the same box meaning that they are related to each other in many aspects.
If you want a better definition here it is :
Definition: Real-time multimedia refers to applications in which multimedia data has to be delivered and rendered in real time; it can be broadly classified into interactive multimedia and streaming media. http://encyclopedia.jrank.org/articles/pages/6877/Real-Time-Multimedia.html
However, Firewalls and NAT devices cause some problems in this aspect .
Thus, I will try to explain what those problems are and what are the mechanisms being developed to overcome those problems .
When to talk about Real time multimedia you might imagine the services below ;
Types of services : Unified communications
- Voice
- Video
- Chat / presence
- Application sharing
Unified communications have some characteristics such as ;
- Real time properties needed
- We tend to find shortest / best path for media because we do not want to face with delay and jitter.
* Delay : Delay is basically latency in the communication. When you say something in Skype , your girlfriend hears it 10 seconds after when you actually say it . It might cause some problems :P .
* Jitter : Jitter is the amount of variation in latency/response time, in milliseconds.
Let's give an example for this ; let's assume that you are expecting your girlfriend to meet you everyday to have a dinner together at 7:30. However the time your gf shows up is not stable meaning that she sometimes shows up around 9:oo sometimes 5:59 ( waits for you and then gives up and leaves :P I do not what kind of girlfriend does that) what would you do in this case ?
The point here is that this situation of variation in meeting time of your girlfriend will result in some decrease of the quality of your relationship for sure .
I believe you got my point :) You might adapt this scenario for Skype . If the jitter is low, then the quality of your realtime voice communication will be better ;)
And assuming I have no firewall, if she makes the call ( she knows my port and IP no) the call works fine because I can use the same link - connection that she opened to call me.
However what happens if we both have firewall ? This is where 3rd party application comes into the picture. This can be a registrar that registers the parts' IP and port number stating to others that "you can reach this registered guy by using this port and IP ". For instance, in order for me and my girlfriend to communicate, we both need to use registrar because we have firewalls that do not let us have a direct communication, right ? By using registrar , I register myself in registrar's database with my IP and port, so my gf does. By this way, Registrar works as a relay service letting us communicate without a problem .
You might ask, why do we need to use registrar while my firewall somehow could be able show them to my girlfriend's firewall ? In this scenario , it simply does not work. Because the IP address and port number that registrar registers are probably seen only by register while in case that her firewall tries to access these port and IP directly ( NAT device might translate them into different numbers for outside of my network) , and they might simply be shown with different IP and port numbers to my gf's firewall.
- Firewall/NAT devices interfere and block communications.
* Cannot send packets to a private address from Internet.
* Firewalls only accept outbound communications initiated from inside.
* NAT : packets from the same port may be seen with different src by different hosts.
What about multimedia ?
- Most protocols for realtime multimedia
* uses multiple ports for a single application. ( 1 port for audio + 1 port for video and so on )
* Most protocols have not been designed for NAT devices. They can send IP+port numbers in the payload. (Upps this is no good) The schema breaks down in NAT devices meaning that NAT violates the system.
Before we outline these protocols, let's first talk about typical Firewall / NAT configurations. These might be the cases on the firewall.
It might also be beneficial to talk about the categorization of NAT devices. They are three categories.
* Designed to allow detection of firewall / NAT properties
(detects If we can have the connection directly or if we need to have a 3rd parties)
* What properties NAT has , discover public addresses assigned to address on the private network
* Discover if the public address seen by one destination host/port can be used another host.
Thanks to STUN servers, each part knows the public IP and port of each other. The devices behind the firewall use STUN servers to figure out these public IP and PORT. No translation of addresses are done in STUN servers.
However in this case of using TCP as alternative for UDP , we might have many problems due to TCP such as packet loss or some distortion in sound or video. Because TCP when packet gets dropped, TCP retransmits it and we come up with delay and jitter that we dont want to have in real time apps .
Of course it is much better always if direct communication is possilbe. But in case it is not possible, TURN is one of the solutions.
With TURN, UDP and TCP communication is possible .
In this point, before we go through the remaining part of the mechanisms, let's talk a little bit about the differences between guaranteed delivery and real time applications.
Guaranteed delivery is something we face with when you download something (like mp3, or media). In this case , we do not care about latency that much. What we care is only the completion of download, right ?
What about a video conference ? or a call from your family by skype ? Can you show some tolerance to jitter or delay ?
Answer should be "NO" , because even a slight jiiter, burst or delay in sound packages, it might distort the conversation meaning that parts may not understand each other.
It uses STUN, TURN and other technologies under the hood.
It basically gathers as many addresses/ports pairs as possible for the parts that want to communicate with each other . This pairs are kept in a prioritized order so that sender and receiver can try these ports and addresses until the communication is set up.
Thanks to ICE, we can avoid a situation in which one part thinks that other part sees him ( video conference ) but actually there is no stream taken in other part. ICE deals with this kind of similar miscommunication problems.
- End to end protocol between clients
- Servers are not direclty involved ( but Turn and Stun servers can be used when needed)
RealTunnel is a product that can be used when everything else is failed .
Doing such operations are not allowed in corporate network.
Another way of modifying the firewall is for voice and video which is for example to use a Session Border Controller. Session Border Controller bypasses the firewall so that actually Session Border Controller works as a firewall, it handles some protocols that it already knows.
Session Border Controller is an Application level gateway which will mask the fact that there are different addresses inside and outside by converting all the payload.
About Application Level Gateways ; Check wiki for more info about Session Border Controller
Wiki says : " It allows customized NAT traversal filters to be plugged into the gateway to support address and port translation for certain application layer "control/data" protocols such as FTP, BitTorrent, SIP, RTSP, file transfer in IM applications etc. In order for these protocols to work through NAT or a firewall, either the application has to know about an address/port number combination that allows incoming packets, or the NAT has to monitor the control traffic and open up port mappings (firewall pinhole) dynamically as required."
However Application Level Gateways ;
* Gateways interfere at application level. it means it breaks firewall principle . Each time the high level protocol changes, application level also needs to adapt to new conditions. It is not always possible to change encrypted data. In some scenarios app. level gateway solution might not be good .
Some protocols having difficulties with NAT and FIREWALLS
What about IPv6 and FIREWALL / NAT
- Do you think will we need NAT in IPv6 ? Because the reason why we use NAT is we have few IP addresses. Therefore we will not need NAT in this sense.
However we can make use of NAT for ;
* Security measure : Topology hiding to prevent host counting by attackers.
* Backward compatibility
- If you have large private network with one million devices with static IP addresses , when changing Internet provider, you dont to modify those 1 million machines. Briefly we will most probably need NAT devices.
There are still no specific standard to support all these scenarios .
However discovery and traversal tools can help find the best path !
STUN, TURN, ICE.
Basically , when to ends want to communicate and if they have firewalls blocks them to communicate directly , a third party mechanism such as registrar is needed for registration. After that , they will know what port and IP to use for direct communication if possible.
Same problems will most probably occur in IPv6.
PS: Almost all of the content of this post has been utilized from the presentation that was given by Knut OMANG in University of Oslo.
First of all, for introduction, let's recall the terms we need to know to cover this topic.
What is Firewall ?
I can basically say that firewall is a wall that protects your computer's ports ( they say that a hacker can reach thousands of ports in your computer ) so that it is defined what kind of connections would be possible through your network.
 |
| http://static.ddmcdn.com/gif/firewall.gif |
I will not go into particulars but for the ones who want to know more about firewall can check this blog ; http://howto-hsk.blogspot.com/2012/03/what-is-firewall.html
But briefly guys, do not destroy your firewall ! we do not want to mess up with hackers :)
Basically Firewall ;
- Blocks all incoming traffic except established connections.
* All communication must be initiated from inside.
- Might block certain protocols
*Some vendors consider UDP dangerous.
- It keeps the track of established communication in a table located in NAT device.
* For TCP connections it is possible to take them into consideration as ESTABLISHED because TCP is a connection based protocol while UDP is connectionless meaning that UDP communication paths are considered as ESTABLISHED only if it has been responded to .
What is NAT ( Network Address Translation ) ?
Cisco says that : Network Address Translation allows a single device, such as a router, to act as agent between the Internet (or ""public network"") and a local (or ""private"") network.Imagine that there are lots of computers, devices conected to Internet behind FIREWALL . By NAT device, let's say located on the firewall ; these devices use only one shared, public IP address to reach outside. As far as I know using NAT devices was introduced because of lack of IPv4 adresses so that many devices could use one public IP adress for ouside the firewall. I believe that most of you have a NAT router in your home. When you use your laptop + smartphone + desktop at home, this is what is going on in your router.
NAT is divided into two groups; Source NAT and Destination NAT.
Source NAT : When you initaite a connection from inside, destination hosts out of yor firewall will see some public IPs assigned by Source NAT.
- Only receiver can detect a sender's port.
* May vary between destination hosts. ( when you communicate with a destination host you get an IP address, while for another destination host you end up with another IP address) .
Destination NAT: When you have a service that you want to allow outside world to benefit from your service which is behind a firewall, you need to tell NAT to map a port with this service so that people on the other side of the wall can access this service.
It should be stated that, firewall and NAT devices are in the same box meaning that they are related to each other in many aspects.
What do we mean by Real Time Multimedia ?
We mean a system that can work real time (e.g people can call you any time when you are out ) irrespective of behind what network infrastructure you are.If you want a better definition here it is :
Definition: Real-time multimedia refers to applications in which multimedia data has to be delivered and rendered in real time; it can be broadly classified into interactive multimedia and streaming media. http://encyclopedia.jrank.org/articles/pages/6877/Real-Time-Multimedia.html
However, Firewalls and NAT devices cause some problems in this aspect .
Thus, I will try to explain what those problems are and what are the mechanisms being developed to overcome those problems .
When to talk about Real time multimedia you might imagine the services below ;
Types of services : Unified communications
- Voice
- Video
- Chat / presence
- Application sharing
Unified communications have some characteristics such as ;
- Real time properties needed
- We tend to find shortest / best path for media because we do not want to face with delay and jitter.
* Delay : Delay is basically latency in the communication. When you say something in Skype , your girlfriend hears it 10 seconds after when you actually say it . It might cause some problems :P .
* Jitter : Jitter is the amount of variation in latency/response time, in milliseconds.
Let's give an example for this ; let's assume that you are expecting your girlfriend to meet you everyday to have a dinner together at 7:30. However the time your gf shows up is not stable meaning that she sometimes shows up around 9:oo sometimes 5:59 ( waits for you and then gives up and leaves :P I do not what kind of girlfriend does that) what would you do in this case ?
The point here is that this situation of variation in meeting time of your girlfriend will result in some decrease of the quality of your relationship for sure .
I believe you got my point :) You might adapt this scenario for Skype . If the jitter is low, then the quality of your realtime voice communication will be better ;)
So what about firewalls ? Let's talk about it by giving some examples .
Given that I would like to call my gf by Skype and she has a firewall that does not allow my network to reach through hers . What happens in this case is that she will not even be able to know that I made a call because the package has been dropped by her firewall.And assuming I have no firewall, if she makes the call ( she knows my port and IP no) the call works fine because I can use the same link - connection that she opened to call me.
However what happens if we both have firewall ? This is where 3rd party application comes into the picture. This can be a registrar that registers the parts' IP and port number stating to others that "you can reach this registered guy by using this port and IP ". For instance, in order for me and my girlfriend to communicate, we both need to use registrar because we have firewalls that do not let us have a direct communication, right ? By using registrar , I register myself in registrar's database with my IP and port, so my gf does. By this way, Registrar works as a relay service letting us communicate without a problem .
You might ask, why do we need to use registrar while my firewall somehow could be able show them to my girlfriend's firewall ? In this scenario , it simply does not work. Because the IP address and port number that registrar registers are probably seen only by register while in case that her firewall tries to access these port and IP directly ( NAT device might translate them into different numbers for outside of my network) , and they might simply be shown with different IP and port numbers to my gf's firewall.
So what is the connection of Firewalls and NAT devices with Multimedia ?
To recap;- Firewall/NAT devices interfere and block communications.
* Cannot send packets to a private address from Internet.
* Firewalls only accept outbound communications initiated from inside.
* NAT : packets from the same port may be seen with different src by different hosts.
What about multimedia ?
- Most protocols for realtime multimedia
* uses multiple ports for a single application. ( 1 port for audio + 1 port for video and so on )
* Most protocols have not been designed for NAT devices. They can send IP+port numbers in the payload. (Upps this is no good) The schema breaks down in NAT devices meaning that NAT violates the system.
We will be talking about TCP/UDP protocols, so we had better have a review of them at this point.
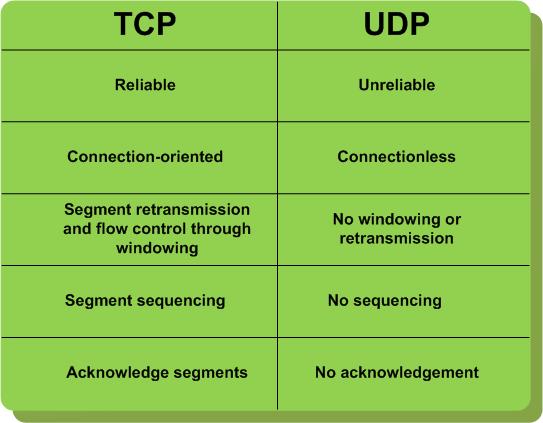 |
| http://www.it20.info/misc/pictures/TCP-clouds-UDP-clouds-design-for-fail-and-AWS1.jpg IF we imagine that we use TCP for a video conference, it is basically no good because sequence is important in TCP , assume that packet 1, packet 2 is received by your device while sender somehow could not send the packet 3 ( router-switch might decide to drop it because of too much traffic) then incoming messages will be hold in receiver's stack without sending them to the device in order to keep everything in order because as we stated the order of messages is important meaning in our scenario that, packet 4-5-6 and so on cannot be sent before the receiver takes packet 3 . After the sender is able to send packet 3 , the receiver stack will know that now the order is ok ( from packet 3 till last packet ) , and then the whole message packets will be delivered once. It means that the interval of receiving packets by the receiver is ruined. And this means jitter which we cannot tolerate in real-time apps. Thats why we prefer UDP over TCP for media transfering, although we might lose some packets in UDP. IF we have to use TCP for some reason in some hopes, then for the rest of the hops, UDP should be prefered. Note: I will talk about UDP and TCP comprehensively in my future posts. |
Mechanisms to enable realtime multimedia services work well in presence of firewalls and NAT devices.
They are actually to detect and handle Firewalls and NAT devices.
1) STUN ( Simple Traversal Utilities for NAT)
2) TURN (Traversal Using Relays around NAT )
3) (N)ICE ( Interactive Connectivity Establishment )
4) Tunneling
5) Modifying / involving the firewall.
4 and 5th solutions are generally not possible to apply . We cannot ask a company to access its firewall configurations, right ? :) we can, but the answer will be "No" unless you are working for that company as a network admin or something .
Before we outline these protocols, let's first talk about typical Firewall / NAT configurations. These might be the cases on the firewall.
- All TCP/UDP allowed + NAT is used on the firewall
- All TCP allowed but UDP is only allowed from add:port that was sent to- and No NAT
- All TCP allowed from inside
- All UDP / TCP blocked
- All direct access to outside is forbidden. (internet access is available by web proxy )
It might also be beneficial to talk about the categorization of NAT devices. They are three categories.
- Endpoint independent mapping ( the most open one ) meaning that when you as a source start a connection with a destination host, this connection can be reused by other destination hosts.
- Address dependent mapping meaning that when you have a connection with a destination host, because it is only address dependent, the ports on that host can use the available connection.
- Address and port dependent mapping is as its name shows that a connection between source and destination host is unique ( source address port + dest. address port) , by this way no other host or ports in the same host can reuse this connection.
1) STUN ( Simple Traversal Utilities for NAT)
* Client/Server based protocol.* Designed to allow detection of firewall / NAT properties
(detects If we can have the connection directly or if we need to have a 3rd parties)
* What properties NAT has , discover public addresses assigned to address on the private network
* Discover if the public address seen by one destination host/port can be used another host.
Thanks to STUN servers, each part knows the public IP and port of each other. The devices behind the firewall use STUN servers to figure out these public IP and PORT. No translation of addresses are done in STUN servers.
What happens if STUN server fails ?
For instance my firewall-NAT might block all UDP for some specific purposes let's say. In this case STUN server fails and tries to communicate with my device through TCP. It succeeds because my NAT device accepts TCP connections. After communicating via TCP , STUN server then keeps communicating with the destination host via UDP ( because the connection is already established and UDP has less links compared to the links that are supposed to be created for TCP) .However in this case of using TCP as alternative for UDP , we might have many problems due to TCP such as packet loss or some distortion in sound or video. Because TCP when packet gets dropped, TCP retransmits it and we come up with delay and jitter that we dont want to have in real time apps .
2) TURN (Traversal Using Relays around NAT )
* Let's say that my device behind the firewall asks a TURN server to give a public port. Then the server directs all to traffic by this port to my device. However this wastes twice more bandwith because imagine that there are two devices and a STUN server in the middle. 1 traffic is caused by while sending something to the Server by another device , and 2nd traffic happens when the server directs this traffic to my device.Of course it is much better always if direct communication is possilbe. But in case it is not possible, TURN is one of the solutions.
With TURN, UDP and TCP communication is possible .
In this point, before we go through the remaining part of the mechanisms, let's talk a little bit about the differences between guaranteed delivery and real time applications.
Guaranteed delivery is something we face with when you download something (like mp3, or media). In this case , we do not care about latency that much. What we care is only the completion of download, right ?
What about a video conference ? or a call from your family by skype ? Can you show some tolerance to jitter or delay ?
Answer should be "NO" , because even a slight jiiter, burst or delay in sound packages, it might distort the conversation meaning that parts may not understand each other.
3) (N)ICE ( Interactive Connectivity Establishment )
It is another recent alternative protocol for exchanging channels for communication.It uses STUN, TURN and other technologies under the hood.
It basically gathers as many addresses/ports pairs as possible for the parts that want to communicate with each other . This pairs are kept in a prioritized order so that sender and receiver can try these ports and addresses until the communication is set up.
Thanks to ICE, we can avoid a situation in which one part thinks that other part sees him ( video conference ) but actually there is no stream taken in other part. ICE deals with this kind of similar miscommunication problems.
- End to end protocol between clients
- Servers are not direclty involved ( but Turn and Stun servers can be used when needed)
4) Tunneling (RealTunnel)
Client on the local network (let's assume we have a mobile phone) finds network connectivity by the help of STUN and some more. This application, RealTunnel, works together with RealTunnelServers located in different geographical locations to find available transport mechanism for the peers in a call.RealTunnel is a product that can be used when everything else is failed .
5) Modifying / involving the firewall. ( Control the FIREWALL)
Actually we all are familiar with modifying our firewalls from the case when we would like to play some games ( after installation you are asked to change your firewall settings to enable the application to do some stuff, right ? ) . However we know that for game players, there is no more important thing than just starting to play the game which can be a big mistake. It might have its the consequences ;)Doing such operations are not allowed in corporate network.
Another way of modifying the firewall is for voice and video which is for example to use a Session Border Controller. Session Border Controller bypasses the firewall so that actually Session Border Controller works as a firewall, it handles some protocols that it already knows.
Session Border Controller is an Application level gateway which will mask the fact that there are different addresses inside and outside by converting all the payload.
About Application Level Gateways ; Check wiki for more info about Session Border Controller
Wiki says : " It allows customized NAT traversal filters to be plugged into the gateway to support address and port translation for certain application layer "control/data" protocols such as FTP, BitTorrent, SIP, RTSP, file transfer in IM applications etc. In order for these protocols to work through NAT or a firewall, either the application has to know about an address/port number combination that allows incoming packets, or the NAT has to monitor the control traffic and open up port mappings (firewall pinhole) dynamically as required."
However Application Level Gateways ;
* Gateways interfere at application level. it means it breaks firewall principle . Each time the high level protocol changes, application level also needs to adapt to new conditions. It is not always possible to change encrypted data. In some scenarios app. level gateway solution might not be good .
Some protocols having difficulties with NAT and FIREWALLS
- SIP (Session Initiation Protocol) is the preferred protocol for VoIP = The protocol can be used for creating, modifying and terminating two-party (unicast) or multiparty (multicast) sessions. Sessions may consist of one or several media streams. (WIKI SAYS so ) TURN , STUN, ICE protocols are made by SIP community.
- H323 and FIREWALL/NAT = Old fashioned protocol that has similar functionalities with SIP .
- OSCAR- AIM, ICQ- and FIREWALL / NAT = Supports most types of firewalls and NATs. Has similar mechanisms as used for SIP
- Skype and Firewall/NAT = Developed for KAZAA . Skype is encrypted (we do not know how it works ) It uses your connection to relay others' calls meaning that they use your bandwidth. When it crashed once in 2007, it was thought to be due to the reason that people (users) had used firewalls and relaying was not that possible in that condition.
- MSNP (MSN) will be replaced by Skype ! :Microsoft bought Skype !
- XMPP
- IPsec is also subject to this problem . Encyrpted VPN solutions use IPsec . IPsec uses AH ( Authentication Protocol) which is an additional header that authenticates the information in the IP header. Ensures that packet header information is not changed by firewall or any other mechanisms . However it is the whole deal of NAT :) and IPsec uses ESP (Encapsulating Security Payload protocol) that encapsulates and encrypts a checksum of the IP payload meaning that port modifications are not possible (because port numbers are in the payload) so if someone tries to modify it , the package gets dropped.
What about IPv6 and FIREWALL / NAT
- Do you think will we need NAT in IPv6 ? Because the reason why we use NAT is we have few IP addresses. Therefore we will not need NAT in this sense.
However we can make use of NAT for ;
* Security measure : Topology hiding to prevent host counting by attackers.
* Backward compatibility
- If you have large private network with one million devices with static IP addresses , when changing Internet provider, you dont to modify those 1 million machines. Briefly we will most probably need NAT devices.
To SUM UP ! (Finally :)
There are still no specific standard to support all these scenarios .
However discovery and traversal tools can help find the best path !
STUN, TURN, ICE.
Basically , when to ends want to communicate and if they have firewalls blocks them to communicate directly , a third party mechanism such as registrar is needed for registration. After that , they will know what port and IP to use for direct communication if possible.
Same problems will most probably occur in IPv6.
PS: Almost all of the content of this post has been utilized from the presentation that was given by Knut OMANG in University of Oslo.
Friday, April 27, 2012
What is a "Distributed System" ?
A distributed system consists of multiple autonomous computers that communicate through a computer network. The computers interact with each other in order to achieve a common goal. A computer program that runs in a distributed system is called a distributed program, and distributed programming is the process of writing such programs. ( WIKI definition )
In this blog, I will try to explain you guys, what are the terms that you are supposed to be familiar with, and what are the topics being studied under DISTRIBUTED SYSTEMS technology.
I hope, it is going to be beneficial .
Please join this journey with me ;)
 | |
| http://www.python.org/files/success/devil/devil-nettree.png |
In this blog, I will try to explain you guys, what are the terms that you are supposed to be familiar with, and what are the topics being studied under DISTRIBUTED SYSTEMS technology.
I hope, it is going to be beneficial .
Please join this journey with me ;)
Subscribe to:
Comments (Atom)